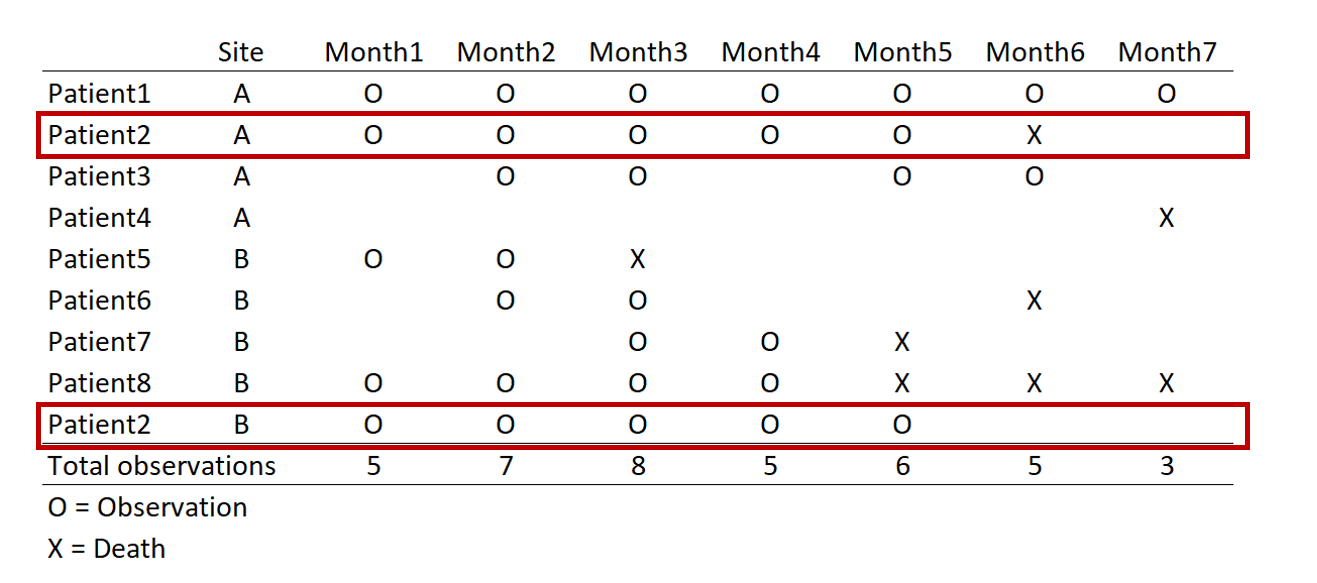
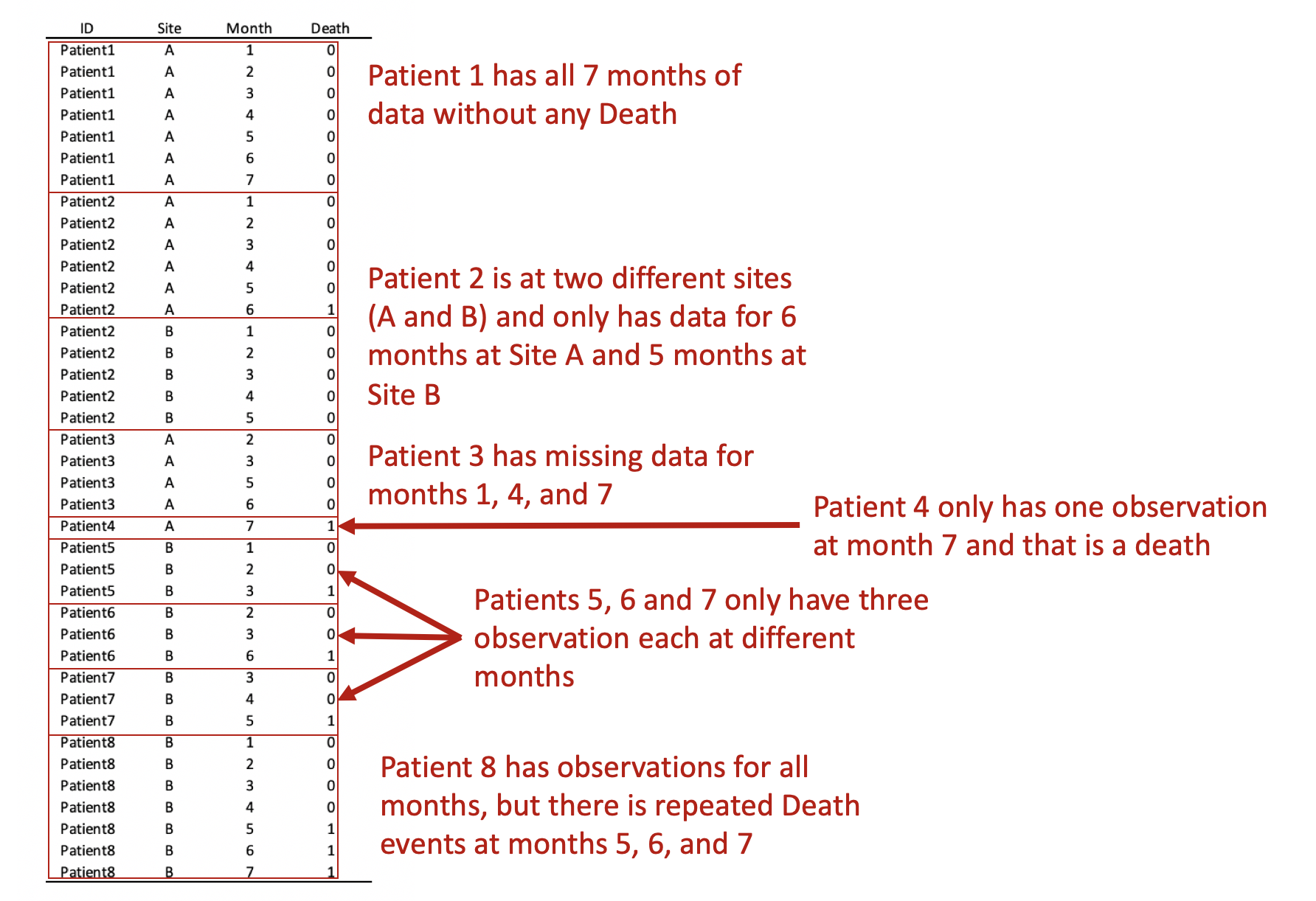
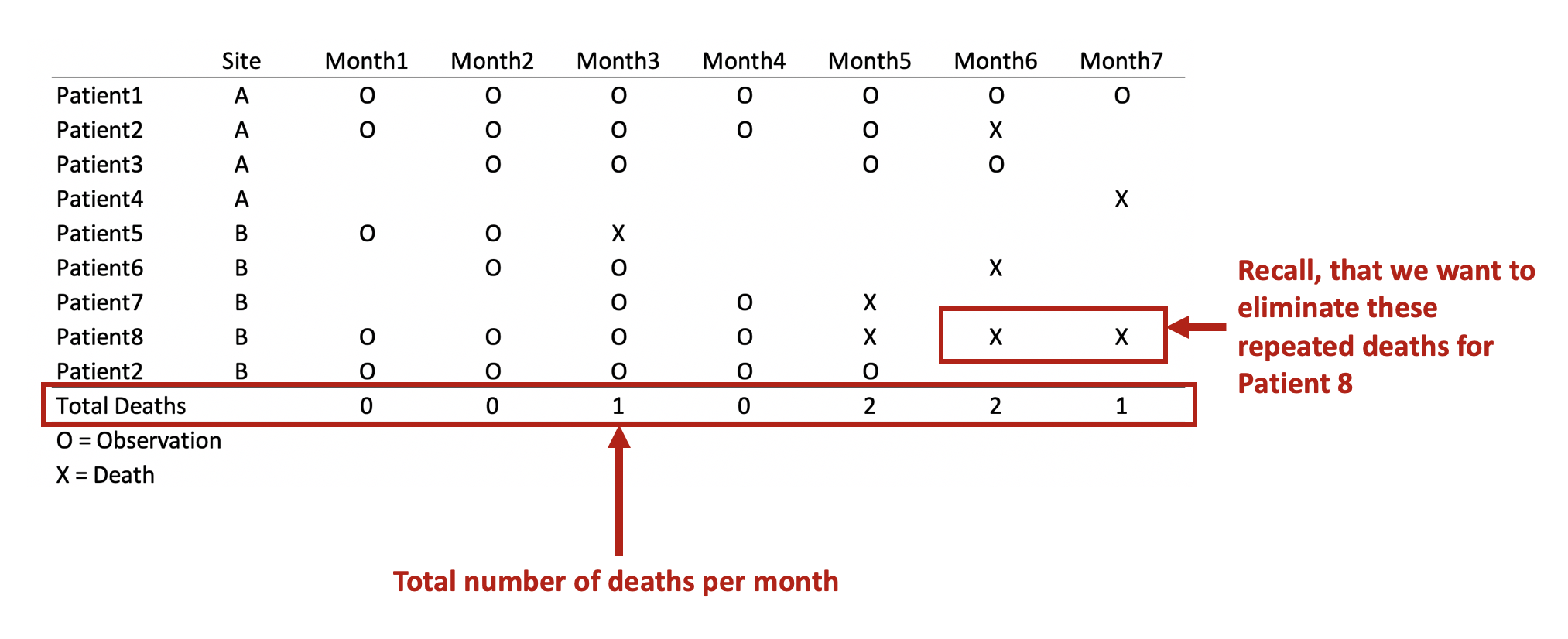
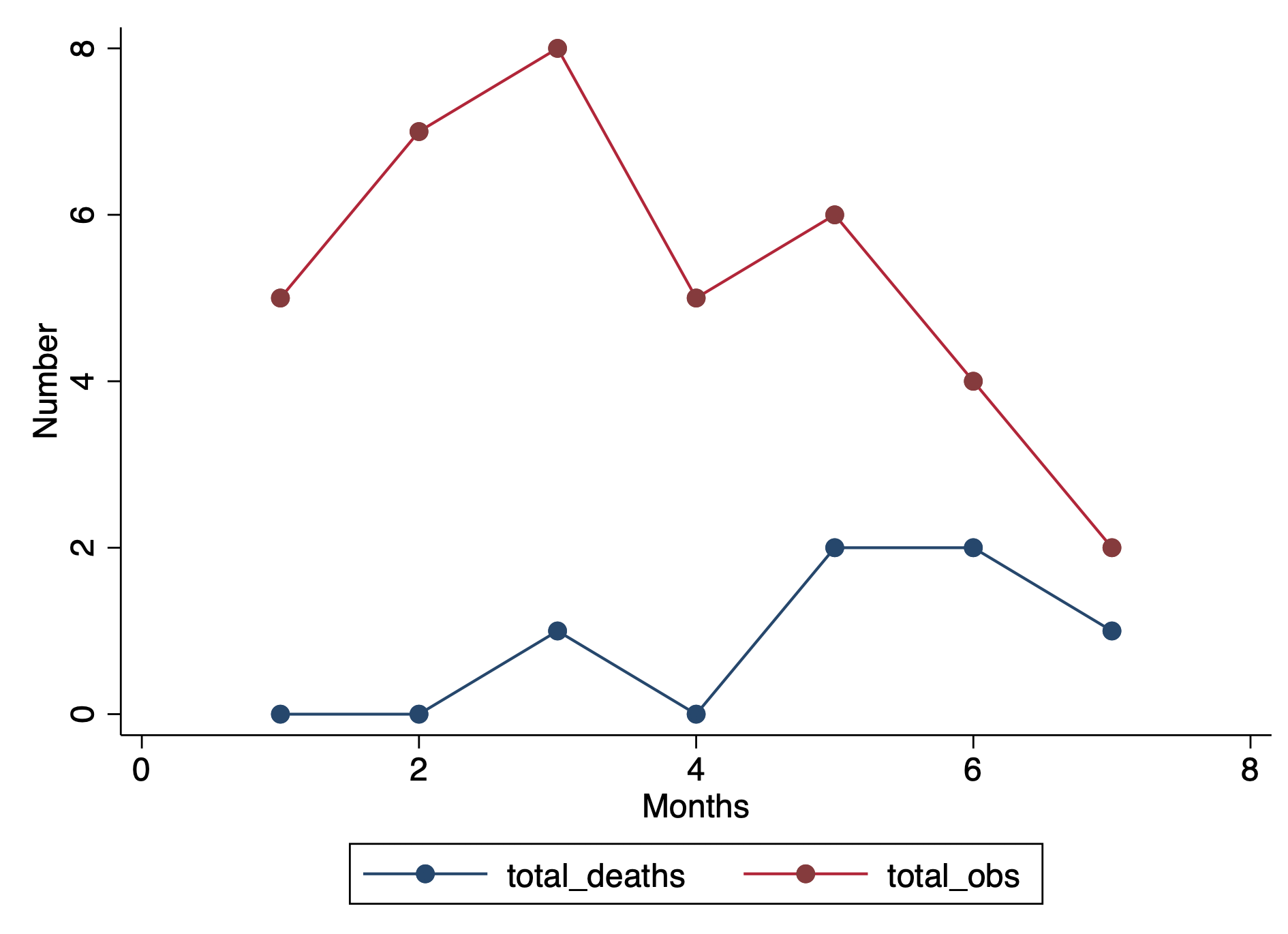
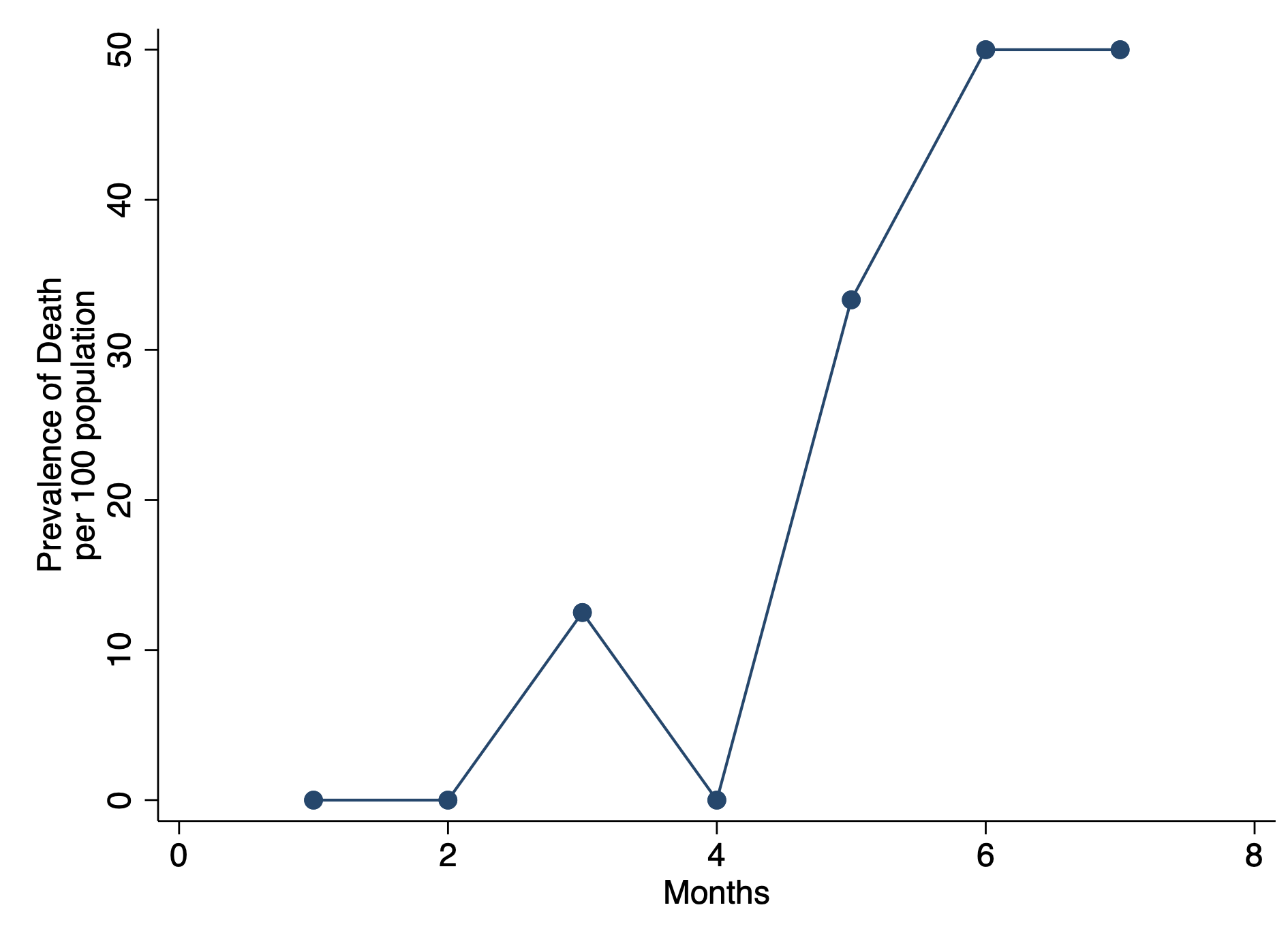
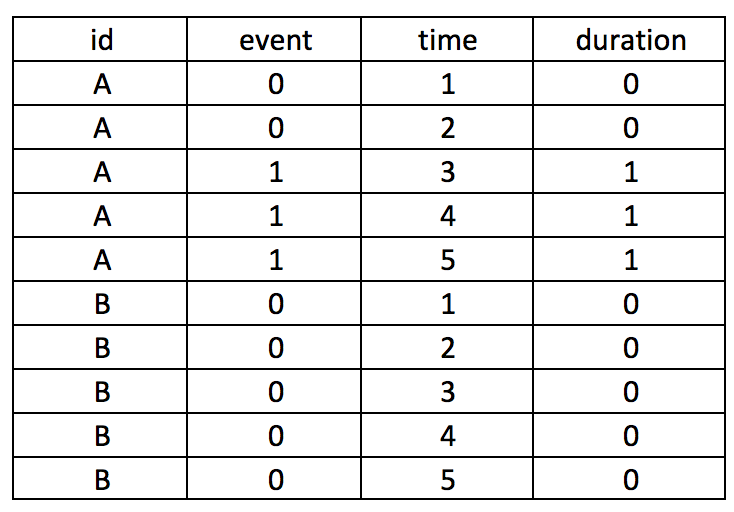
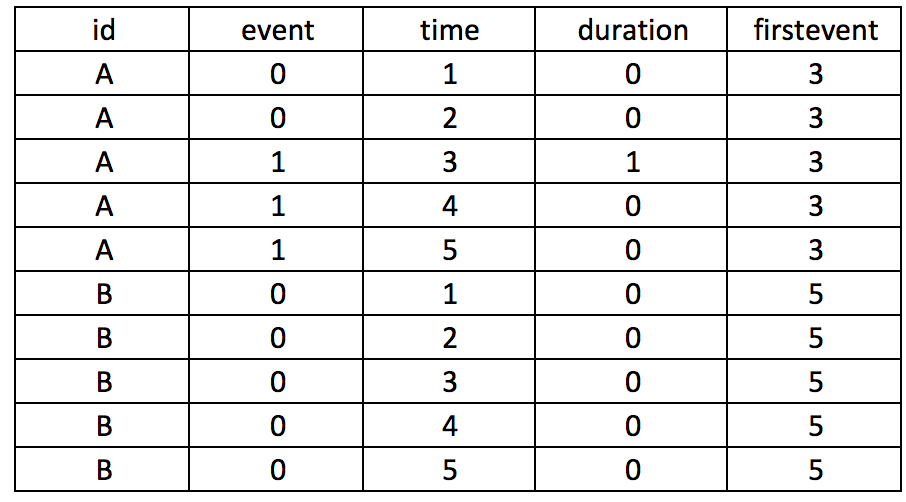
I wrote a tutorial on how to handle immortal time bias with survival analysis using Stata. In the tutorial, I used a time-varying predictor for the grouping variable and assigned the period before exposure to the control group. This was inspired by the paper Redelmeier and Singh wrote on “Surival in Academy Award-Winner Actors and Actresses.” There was a lot of debate about the rigor of their analyses, and Sylvestre and colleagues re-analyzed the data with immortal time bias in mind. This tutorial uses data from Sylvestre and colleagues to re-create their results.
The tutorial is on my RPubs page. Data used for the tutorial is located on my GitHub page.
To load the data, you can use the Stata import command
import delimited "https://raw.githubusercontent.com/mbounthavong/Survival-analysis-and-immortal-time-bias/main/Data/data1.csv"